
Spoločnosť Oracle so značnou dávkou neskromnosti označuje svoje databázové riešenie Exadtata za najrýchlejší databázový server na svete. Pojem “server” sa dá chápať viacerými spôsobmi. Databázový server je balík softvérových prostriedkov jednak pre prácu s údajmi, ale aj pre organizovanie a realizáciu prístupu klientov k týmto údajom. Databázová platforma Oracle 11g zapuzdruje databázu, databázový server, súbor nástrojov pre správu a zabezpečenie údajov v databáze. Exadata je komplexné riešenie, ktoré pozostáva z výkonného hardvéru, databázovej platformy Oracle 11g a softvéru na najnižšej úrovni, ktorý umožňuje optimálnu orchestráciu hardvéru a databázovej platformy.
Okrem nahradenia mechanických diskových médií polovodičovými úložiskami sa na vysokom výkone podieľa aj kompresia údajov a Exadata Smart Scan .
Exadata Hybrid Columnar Compression
Pri ukladaní údajov sa využíva špeciálny algoritmus hybridnej stĺpcovej kompresie Exadata Hybrid Columnar Compression (EHCC), ktorá umožňuje revolučné zvýšenie výkonu pri súčasnom znížení nákladov. Na prvý pohľad to však znie ako rozpor. Kompresia je náročná na kapacitu procesorov, takže logicky by malo dochádzať k úspore nákladov za cenu poklesu výkonu. V súčasnosti však výkon procesorov rastie rýchlejšie než výkon ostatných častí serverov. Z technického hľadiska sa nielen výrazne šetrí úložná kapacita na fyzických médiách, ale znižuje sa aj záťaž na úrovni I/O. Priemerná teoretická úspora sa pohybuje na úrovni 10 až 15 krát v závislosti na úrovni implementácie hybridnej stĺpcovej kompresie. V praxi dosahované výsledky sú oveľa priaznivejšie – benchmarky na reálnych údajoch zákazníkov, ktoré prirodzene obsahovali pomerne veľa duplicitných údajov ukázali v niektorých prípadoch až dvestonásobnú úsporu. Samozrejme všetko závisí od charakteru údajov, od úrovne redundancie a od toho či databázové tabuľky obsahujú takzvané riedke stĺpce. Takéto tabuľky majú veľký počet atribútov, no v mnohých záznamoch sa nie vždy všetky atribúty využívajú. Nie je zriedkavý prípad keď sa z niekoľkých desiatok, alebo stovák atribútov využívajú v niektorých záznamoch len dva-tri a ostatné majú hodnotu NULL. Typickým príkladom sú napríklad tabuľky obsahujúce dimenzie v dátových skladoch. Aj keď by sme uvažovali priemernú úroveň kompresie 10x, takéto riešenie môže výrazne znížiť a často aj eliminovať potrebu nákupu nového úložisko aj počas niekoľkých rokov. Napríklad na uloženie 100 TB databázy je potrebná fyzická úložná kapacita 10 terabajtov fyzickej pamäte. EHCC je možné využiť aj v rámci riadenia životného cyklu dát.
Kompresiu je možné aktivovať na úrovni tabuľky alebo partície a to v dvoch rôznych módoch Warehouse Compression a Archival Compression, pričom každý z nich má svoje výhody a nevýhody, čo ich predurčuje pre špecifické scenáre.
– Warehouse Compression – kompresia optimalizovaná pre dopytovanie, využívaná v DWH aplikáciách, kde sú dáta často dopytované. Vďaka odhadovanému 10-násobnému kompresnému pomeru sa počet I/O operácií zníži na desatinu a tým pádom sa dosahuje zlepšenie výkonu dotazov.
– Archival Compression – kompresia optimalizovaná pre maximálne úspory miesta na disku, využíva sa pre historické dáta, ktoré sú dopytované zriedkavo. Typicky sa dosahuje 15-násobný kompresný pomer.
Ako EHCC kompresia funguje?
V klasických databázach sú údaje organizované v rámci databázy bloku v riadkovom formáte, kde sú všetky údaje pre stĺpce daného riadku postupne uložené v rámci jedného bloku databázy. Toto nie je optimálne pre klasické metódy kompresie, nakoľko v blokoch sú vedľa seba údaje z viacerých stĺpcov s rôznymi typmi údajov, čo obmedzuje dosiahnutý kompresný pomer. Oveľa výhodnejšie je ukladať údaje do blokov po jednotlivých stĺpcoch. Takto sa v bloku údajov koncentrujú údaje rovnakého dátového typu, čo spravidla umožňuje dosiahnutie oveľa väčšieho kompresného pomeru.
Údaje sú počas ukladania rozdelené do menších celkov, tzv. Compression Unit a v rámci nich utriedené podľa stĺpcov, pričom každý stĺpec je samostatne komprimovaný a uložený na disk
Samozrejme všetko má svoje výhody aj nevýhody. Ukladanie dát zo stĺpcov s rovnakým dátovým typom do blokov na jednej strane výrazne zvyšuje kompresný pomer, no na druhej strane ukladanie dát týmto spôsobom, čiže čistá stĺpcová kompresia môže negatívne ovplyvniť výkon databázy pri dopytovaní na údaje z viacerých stĺpcov, prípadne pri ukladaní a aktualizácii údajov. Preto Exadata využíva hybridnú stĺpcovú kompresnú technológiu ktorá ukladanie po stĺpcoch kombinuje s cylindrickými metódami pre ukladanie dát. Tento hybridný prístup umožňuje dosiahnuť kompresné pomery typické pre stĺpcovú kompresiu bez toho aby sa prejavili funkčné nedostatky tejto metódy v klasickom ponímaní. Tabuľky sú zoskupené do množín z niekoľko tisíc riadkov. Tieto množiny sa nazývajú Compression Units (CU). Vo vnútri CU sú údaje organizované podľa stĺpcov a potom skomprimované.
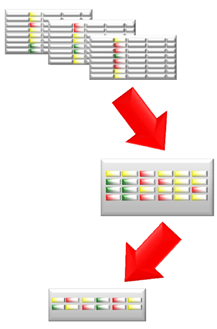
Princíp názorne ilustruje obrázok. hodnoty stĺpcov pre množinu riadkov sú najskôr zoskupené a následne komprimované.
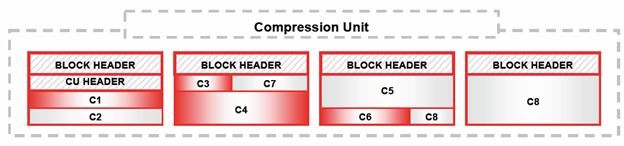
Logická kompresná jednotka
Do dátových skladov sa údaje zavádzajú cez “bulk loading” techniky. Tabuľky na ktoré je aplikovaná hybridná stĺpcová kompresia je možné meniť pomocou klasickej manipulácie s dátami prostredníctvom príkazov jazyka DML, ako sú napríklad INSERT a UPDATE.
Exadata Smart Scan
Dotazy, ktoré vykonávajú table scan sú presmerované na storage server, kde sú vykonávané oveľa efektívnejšie. Filtrovanie riadkov na základe klauzuly WHERE, filtrovanie stĺpcov a vykonávanie join operácií prebehne na storage serveri, pričom DB serveru sú zaslané len výsledné dáta (nie bloky s požadovanými informáciami). Takéto spracovanie znižuje záťaž DB servera a niekoľkonásobne redukuje objem prenášaných údajov. Exadata Smart Scan umožňuje až 10 násobnú redukciu prenosu údajov, pričom pre aplikácie je táto metóda transparentná. Situáciu najlepšie ilustruje dvojica obrázkov
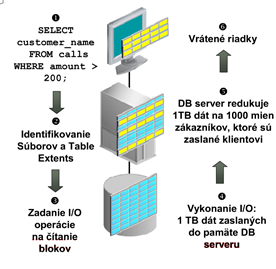
Klasický scan
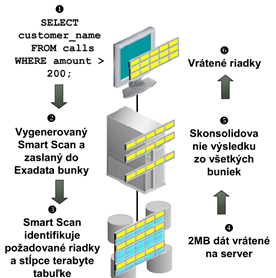
Exadata Smart Scan
